CUDA技术
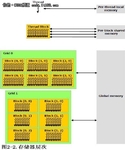
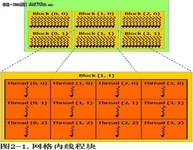
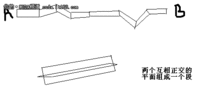
在执行期间,CUDA线程可能访问来自多个存储器空间的数据,如图2-2所示。每个线程有私有的本地存储器。每个块有对块内所有线程可见的共享存储器,共享存储器的生命期和块相同。所有的线程可访问同一全局存储器。
本章引入了CUDA编程模型背后的主要概念,方式是概述它们是怎样使用C语言表示的。更多的关于CUDA C的描述在第三章。

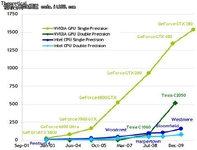
市场对实时、高清晰度的三维图形具有无法满足的需求,由于这种需求的推动,可编程图形处理器(GPU)已经演化成高并行度,多线程,拥有强大计算能力和极高存储器带宽的多核处理器。
明基MS614支持3D显示功能,性能为入门娱乐投影机水平,且具备U盘直接演示功能,适合小型商务演示以及个人家庭娱乐选用。目前该机在武汉恒友世纪的售价为2780元(网购地址:www.011buy.com),并赠送激光笔,感兴趣的朋友不妨多关注下!
NVIDIA Gelato、Tesla、CUDA是一股对传统基于CPU的渲染器挑战的力量。GPU在诸多方面具有软件实现无可比拟的优势比如光栅化部分,遮挡剔除,以及潜在的并行计算能力,但是编程性实在缺少基于CPU的自由度,所以在相当的一段时间内还无法充分发挥性能。

充分意识到GPU海量的吞吐和强悍的浮点计算能力,将极高提高程序性能,也能让充分发挥显卡的价值,GPU作为电脑上2个可编程的高性能芯片之一,长期以来都没得到普通程序员应有的重视,主要因为其编程麻烦,资料工具欠缺。
2011年11月10日,据NVIDIA官方宣布CUDA Toolkit 4.1 RC1版本发布,目前CUDA注册开发者已经可以下载。CUDA开发者请登录官网下载http://nvdeveloper.nvidia.com/或者立即注册下载https://registration.nvidia.com/Cuda.aspx。发布者期待通过注册开发者的反馈了解使用新版本中的个人体会(优点与缺点)。

本文介绍了作者在编写CUDA代码的过程中,在Debug下编译有错而Release下无错的解决方法。

本文主要分析CUDA SDK sample如何同OpenGL相结合.我们可以看到, 渲染的所有效果都是由CUDA通过volume render产生的, 最后OpenGL只是把结果作为一张图片贴在我们的视口上. 这里面有两个小细节glPixelStorei()函数修改数据对齐的单位, 详细介绍在这里.
前一篇为大家介绍了在Mac环境下安装CUDA 4.0的准备工作,这篇将详细为大家介绍安装CUDA 4.0的详细步骤。
基于CUDA的图像亮度直方图统计,算法:1、先计算原始图像每个像素的亮度:u = (unsigned char)(0.299f * r + 0.587f * g + 0.114f * b)。2、用一个256大小的数组统计每个亮度的点的数量。

本文主要分析VolumeRender中涉及到的一些图形算法:Ray casting、 直线平面求交。Volume Render通常用来绘制几何图形难以表现的流体、云、火焰、烟雾等效果,流行的volume render算法有:ray casting、texture-based volume rendering。SDK例子使用的是Ray casting算法。
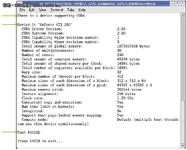
通过之前的文章,笔者介绍了如何在Linux环境下安装CUDA 4.0。因为Linux系统版本众多,因此即使按照相关步骤进行操作,也可能会出现问题。如何验证安装正确与否是本文将要讲解的内容。
在前面的文章中,笔者向大家介绍了如何在Linux环境下安装CUDA 4.0的准备工作,本文将会详细讲解在Linux环境下安装、配置CUDA 4.0的步骤和注意事项。
一个很简单的CUDA程序,适合刚刚接触CUDA的人了解CUDA的工作原理,以及与OpenCV结合的基本用法。
实际上在 nVidia 的 GPU 里,最基本的处理单元是所谓的 SP(Streaming Processor),而一颗 nVidia 的 GPU 里,会有非常多的 SP 可以同时做计算;而数个 SP 会在附加一些其他单元,一起组成一个 SM(Streaming Multiprocessor)。几个 SM 则会在组成所谓的 TPC(Texture Processing Clusters)。

Nvidia公司推出了 Parallel Nsight 2.0 RC,完美支持VS2010和VS2008SP1,支持CUDA 4.0。让我们省去了配置环境参数的烦恼。
在建立雷达虚拟操作系统或维修训练系统时,显示器的仿真效果直接影响模拟器的训练效果。目前制约余辉实现的主要瓶颈是余辉效果带来的庞大的计算量,使得效果较好的余辉扫描线转速难以超过10转/s,如果要提高转速,则需要以牺牲显示画质为代价。



- 40位软件名人榜单出炉,60后占半壁江山!
- 于企业应用程序而言,Go比Java更明智!
- 从0到700万,钉钉只用3年,原因就是快准狠!
- 网络间谍竟持续8年活跃于中国 终被成功捕获
- "漏洞攻击拦截"功能助火绒企业产品C位出道
- MWC 2018上海:大量5G智能概念产品亮相
- 三大角度PK,Go语言和Node.js谁胜谁负?
- 思科曹图强:勒索软件将打破安全防御平衡
- 服务器价格指导 6月双路塔式服务器选购
- 佳能全力助推 设计研究院文印转印升级
- 安装到部署 火绒安全企业新品究竟有多"简"?
- 618盛况空前 斐讯商城祭出了“杀手锏”
- 玩转toB安全市场! 火绒企业安全产品评测
- 速看 斐讯天天链N1“掘金”上手攻略完整版
- 40位软件名人榜单出炉,60后占半壁江山!
- 区块链原理是什么?如何开发区块链程序?
- 区块链技术的这些特征 你都了解哪些?
- 于企业应用程序而言,Go比Java更明智!
- Java生态系统面临的最大问题是质量恶化
- 6.18大促全场大放价! 斐讯祭出几款无线神器










