CUDA技术
CUDA 编程模型将 CPU 作为主机 (Host) , GPU 作为协处理器 (co-processor) 或者设备 (Device). 在一个系统中可以存在一个主机和多个设备。 CPU 主要负责进行逻辑性强的事物处理和串行计算, GPU 则专注于执行高度线程化的并行处理任务。

开发GPUMeanShift的过程中,遇到的复杂问题,这就是CPU与GPU之间的非连续内存拷贝,以下是解决方法。按照以前的思路,对于一段连续CPU内存。
光把CUDA SDK中的usertype.dat文件复制到IDE目录下,只能让VS支持CUDA的关键字高亮显示;而VS好用的代码折叠却不能应用到CU文件上,真是让人气愤.于是我就翻翻注册表,发现了可以让VS支持CU文件代码折叠的方法.
CUDA的DLL开发其实和一般的C/C++的DLL开发是一个原理,当然,DLL的开发就有几种方式,这里就讲最容易理解的,也最直接的方式,然后把代码放出来。大家自己可以琢磨一下其它的方式。
由nvcc生成的通用计算程序分为主机端程序和设备端程序两部分。那么,一个完整的CUDA程序是如何在CPU和GPU上执行的呢?在这一节,我们不仅将介绍CUDA的编程模型如何映射到硬件上,还会介绍GPU的硬件设计如何对CUDA程序效率产生影响。
请先看一段教程:到目前为止,我们的程序并没有做什么有用的工作。所以,现在我们加入一个简单的动作,就是把一大堆数字,计算出它的平方和。要利用 CUDA 进行计算之前,要先把数据复制到显卡内存中,才能让显示芯片使用。因此,需要取得一块适当大小的显卡内存,再把产生好的数据复制进去。
欢迎继续阅读本系列文章的第5部分,在这篇文章中,我将介绍如何在GPU(Grid)上启动多维块。我们将创建和上一篇文章一样的程序,但这一次我们要显示二维数组块,每个块显示一个计算的值。

本文详细讲解了内联PTX汇编程序开发的方法。通常存储器写操作是作为输出操作,但有时会存在同步隐患,或者想避免编译器对存储操作的优化,这时可以使用”memory”指示字。 总体来说inline PTX现在还比较初级,有些功能还不能使用,比如指令操作数只能是标量,不支持矢量。
CUDA中(如果在nVIDIA的GPU上,这些技巧同样适用于OpenCL),通常显式的让数据按照warp模式分配执行(指令在硬件层自动按照warp派发),通常可让程序性能优成倍提升。在这个系列中我们将介绍多个以warp mode执行且带来明显性能提升的例子(当然,计算规模要足够大)。
近日,CUDA 4.0已经对注册开发者开放,其中增加了不少的功能。其中P2P(Peer-to-Peer )与UVA(Unified Virtual Address Space )的引进最为大家关心。这里与大家一起分享下SDK中的simpleP2P这个例子,他展示了如何使用这两个功能。
CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。从CUDA体系结构的组成来说,包含了三个部分:开发库、运行期环境和驱动。开发库是基于CUDA技术所提供的应用开发库。
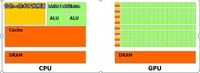
自2011年2月28日NVIDIA公司宣布新版GPU并行通用计算架构CUDA 4.0至今,已经出现了两个版本,分别是RC和RC2。RC2版本在功能特性上没有明显变化,在功能上主要的改进方向是简化并行编程,让更多开发人员能够将应用程序移植到GPU平台。
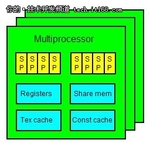
这里我们会简单介绍,NVIDIA 目前支持 CUDA 的 GPU,其在执行 CUDA 程序的部份(基本上就是其 shader 单元)的架构。主要的数据源包括:NVIDIA 的 CUDA Programming Guide 1.1、NVIDIA 在 Supercomputing '07 介绍 CUDA 的 session,以及 UIUC 的 CUDA 课程。
在《runtime API创建CUDA程序》中,我们做了一个计算一大堆数字的平方和的程序。不过,我们也提到这个程序的执行效率并不理想。当然,实际上来说,如果只是要做计算平方和的动作,用 CPU 做会比用 GPU 快得多。这是因为平方和的计算并不需要太多运算能力,所以几乎都是被内存带宽所限制。

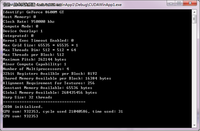
之前我们为大家介绍了《利用GPU计算加法》这篇文章,今天介绍一下CUDA设备的相关属性,只有熟悉了硬件是相关属性,是怎么工作的,就能写出更适合硬件工作的代码。cudaDeviceProp这个结构体记录了设备的相关属性。
前面介绍的计算平方和的程序,似乎没有什么实用价值。所以我们的第二个 CUDA 程序,要做一个确实有(某些)实用价值的程序,也就是进行矩阵乘法。而且,这次我们会使用浮点数。虽然矩阵乘法有点老套,不过因为它相当简单,而且也可以用来介绍一些有关 CUDA 的有趣性质。
在《CUDA程序优化策略》这篇文章中,我们介绍过CUDA优化的常见策略。今天我们会对CUDA优化策略进行详细讲解。CUDA程序的优化至关重要,因此要做好优化工作需要掌握一定的技巧。
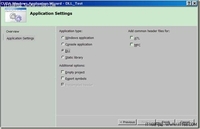
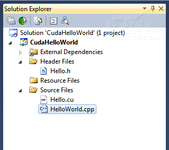
现在最新的CUDA工具包已经发布,与Visual Studio的集成也变得更容易了,在这篇文章中,我将介绍如何使用Visual Studio 2008创建一个CUDA应用程序。

CUDA目前有两种不同的 API:Runtime API 和 Driver API,两种 API 各有其适用的范围。由于 runtime API 较容易使用,一开始我们会以 runetime API 为主。


- 40位软件名人榜单出炉,60后占半壁江山!
- 于企业应用程序而言,Go比Java更明智!
- 从0到700万,钉钉只用3年,原因就是快准狠!
- 网络间谍竟持续8年活跃于中国 终被成功捕获
- "漏洞攻击拦截"功能助火绒企业产品C位出道
- MWC 2018上海:大量5G智能概念产品亮相
- 三大角度PK,Go语言和Node.js谁胜谁负?
- 思科曹图强:勒索软件将打破安全防御平衡
- 服务器价格指导 6月双路塔式服务器选购
- 佳能全力助推 设计研究院文印转印升级
- 安装到部署 火绒安全企业新品究竟有多"简"?
- 618盛况空前 斐讯商城祭出了“杀手锏”
- 玩转toB安全市场! 火绒企业安全产品评测
- 速看 斐讯天天链N1“掘金”上手攻略完整版
- 40位软件名人榜单出炉,60后占半壁江山!
- 区块链原理是什么?如何开发区块链程序?
- 区块链技术的这些特征 你都了解哪些?
- 于企业应用程序而言,Go比Java更明智!
- Java生态系统面临的最大问题是质量恶化
- 6.18大促全场大放价! 斐讯祭出几款无线神器










