CUDA
由于最近要做Cg运算平台到Cuda平台的算法移植工作,所以最近正考虑做一个GPGPU和Cpu运算效率的比较公正,但是由于手头的笔记本电脑仅仅对Cuda支持不好(上次安装Cuda后显卡烧坏了),所以这里先做一个使用Cg编程的矩阵运算(加法):

离散数据的二维卷积: 其中,Ar、Ac分别是A的行数与列数。应用很多,比如对图像做高斯平滑(去噪),拿高斯核与输入图像做卷积。 convolutionSeparable之所以”Separable”,是因为它在row、col两个维上分别做了卷积操作。
在上一篇的《nVidia CUDA API》中,已經大概介紹了一些寫 CUDA 程式時,必須知道的 API;接下來,就先開始簡單的 CUDA 程式吧! 這邊舉一個簡單的向量相加的程式來當例子。
CUDA 的 API 架構,大概分成「C 語言的 extension」、「runtime library」兩部分。extension 的部分,提供了 C 的一些延伸,來訂一 CUDA 的變數、程式等等;在最簡單的 case 裡,應該只要用到 extension 的部分就夠了~而 runtime library 的部分,則又提供了一些 CUDA device 的控制函式,以及一些針對 GPU 編寫的特殊的函式。
在《nVidia CUDA API(上)》的部分,已經大致說明了 extension 的部分;這邊要來講的則是 runtime library 的部分。
在运用cuda进行md5crack的时候,遇到一个问题,既cuda是并行的,他不向cpu那样会一句一句的执行。因此在执行过程中有用的线程在当前grid中的索引就显得很重要,那为我们生成md5的字典起到了非常重要的作用。但是,也因为他的串行,很多事情不像cpu那样方便了,因为我们必须从gpu的角度去看问题。现在就让我们看一下具体的问题。
在《nVidia CUDA API(下)》中有提到 CUDA SDK 裡有提供一些基本的裝置管理的界面,也就是像是「cudaSetDevice( int )」這一類的函式。基本上,這些 function 的功用、用法在該篇文章中講的應該是夠了~
延續上一篇講 thread block,這一篇能然是繼續講 transpose 這個範例程式;不過這一篇,則是將焦點放在 shared memory 的使用,也就是 transpose 這個最佳化過的 kernel 函式。
在 Heresy 寫的前兩篇 sample 程式(VectorAdd、DeviceInfo)裡,都是很簡單的程式;像 VectorAdd 裡,也是刻意把 vector size 設小,避掉 thread 數目超過 block 限制的問題,以避免要用到複數個 block。但是實際上,應該都是會超過 thread block 的大小限制的(畢竟 G80 的 block 大小只有到 512…)~
今天尝试用cuda把FFT实现,遇到了难题。直接调用cufft库的话,内存拷贝与数据处理的时间比大约是1:2。但是据说cufft并不是最高效的,所以想自己锻炼一下。
通用的一些接口,前一章节也有提高过:数学函数,时间函数,同步函数,原子操作; 2.控制Device的函数;就是得到设备信息,管理设备信息的函数。设置那块显卡工作,得到那块显卡的性能。
以下为VS2005的配置,VS2003和VS2008与此类似。 1、安装Visual Studio 2005环境。 2、安装开发助手Visual Assist X。 3、从 http://www.nvidia.cn/object/cuda_get_cn.html 下载CUDA相关软件,并按次序安装。
纹理存储器(texture memory)是一种只读存储器,由GPU用于纹理渲染的的图形专用单元发展而来,因此也提供了一些特殊功能。纹理存储器中的数据位于显存,但可以通过纹理缓存加速读取。在纹理存储器中可以绑定的数据比在常量存储器可以声明的64K大很多,并且支持一维、二维或者三维纹理。在通用计算中,纹理存储器十分适合用于实现图像处理或查找表,并且对数据量较大时的随机数据访问或者非对齐访问也有良好的加速效果。
开始接触CUDA,我安装好后完全不知道怎么运行demo,当然也没有见到详细的安装说明。下面说说我的经验。
以下内容摘自CUDA编程手册 版本2.1 并参考并引用了2.0中文版编程手册中的内容,并修正了一些术语和错误。本章节介绍CUDA编程模型的主要的概念并勾画出其是如何以C的形式进行表述。关于对应CUDA的C的描述的更加详细的内容将会在第四章给出。
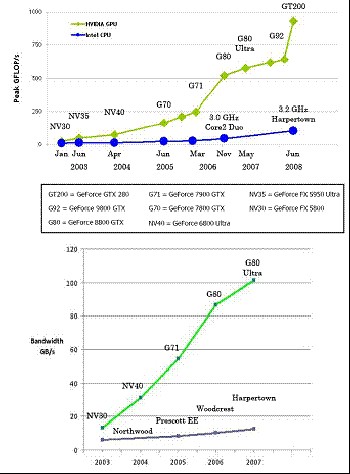
CUDA和支持CUDA的设备正在共同发展,在新一代产品中提供了更多的性能和功能。NVIDIA最近引入的GeForce 200系列和Tesla 10系列产品,展示了这种发展的迅速,其硬件功能几乎是上一产品线同一价格水平可用功能的两倍,而且200系列还增加了一些有价值(而且不可或缺)的新功能。
本专栏细心的读者已经了解了之前专栏中讨论的两个反向数组示例,可能对为什么共享存储器版本比全局存储器版本速度更快仍然感到困惑。请回想一下共享存储器版本reverseArray_multiblock_fast.cu,内核将数组数据从全局存储器复制到共享存储器,然后再复制回全局存储器,而较慢的内核reverseArray_multiblock.cu只将数据从全局存储器复制到全局存储器。因为全局存储器性能比共享存储器慢100-150倍,所以慢得多的全局存储器性能占据了两个示例的绝大部分运行时。为什么共享存储器版本更快?
平时我们使用的内存都是Pageable(交换页)的,而另一个模式就是Pinned(Page-locked),实质是强制让系统在物理内存中完成内存申请和释放的工作,不参与页交换,从而提高系统效率,需要使用cudaHostAlloc和cudaFreeHost来分配和释放。
受到来自实时、高分辨率3D图形的市场的永不满足需求的推动,可编程的图像处理单元(Graphic Processor Unit, GPU)演化为具备强大计算能力以及高内存带宽的高度的并行性,多线程性,多核处理器 。


- 40位软件名人榜单出炉,60后占半壁江山!
- 于企业应用程序而言,Go比Java更明智!
- 从0到700万,钉钉只用3年,原因就是快准狠!
- 网络间谍竟持续8年活跃于中国 终被成功捕获
- "漏洞攻击拦截"功能助火绒企业产品C位出道
- MWC 2018上海:大量5G智能概念产品亮相
- 三大角度PK,Go语言和Node.js谁胜谁负?
- 思科曹图强:勒索软件将打破安全防御平衡
- 服务器价格指导 6月双路塔式服务器选购
- 佳能全力助推 设计研究院文印转印升级
- 安装到部署 火绒安全企业新品究竟有多"简"?
- 618盛况空前 斐讯商城祭出了“杀手锏”
- 玩转toB安全市场! 火绒企业安全产品评测
- 速看 斐讯天天链N1“掘金”上手攻略完整版
- 40位软件名人榜单出炉,60后占半壁江山!
- 区块链原理是什么?如何开发区块链程序?
- 区块链技术的这些特征 你都了解哪些?
- 于企业应用程序而言,Go比Java更明智!
- Java生态系统面临的最大问题是质量恶化
- 6.18大促全场大放价! 斐讯祭出几款无线神器










