hadoop
现在,所有的品牌都离不开社交媒体,社会化营销也已经成为品牌营销的深度组成部分,而品牌对社交媒体营销在平台的选择上,微博成了首选。 如何运用好微博,让品牌不仅是单方信息传递,同时还能带来消费者的参与?如何通过

看似NoSQL数据库在过去几年中迎来了发展的春天,而传统数据库却缺乏施展空间。其实情况正好相反,“结构化查询语言(SQL)“实际已经在原本看似难以发挥的领域占据了统治地位,这就是“大数据”。近日在美国召开的Hadoop峰会上,众多新产品与合作都围绕“大数据”分析这一核心展开。其中最令人惊讶的在于,一项已经存在数十年的技术伴随着海量数据处理方案再次出现在人们面前。

作为由VMware与EMC共同创立的后起之秀,Pivotal正努力面向未来打造应用程序平台,并在近日推出了其第一款基于Hadoop大数据处理工具的产品。
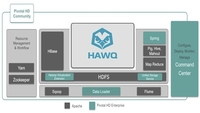
并行数据库是指那些在无共享的体系结构中进行数据操作的数据库系统。这些系统大部分采用了关系数据模型并且支持SQL语句查询,但为了能够并行执行SQL的查询操作,系统中采用了两个关键技术:关系表的水平划分和SQL查询的分区执行。
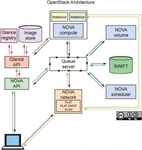
这两种答案都有企业在实践。“Hadoop跑在OpenStack上”可以参考《Project Savanna:让Hadoop运行在OpenStack之上》,“OpenStack部署到Hadoop上”则重点可查阅本文。随着企业开始同时利用云计算和大数据技术,现在应当考虑如何将这些工具结合使用。在这种情况下,企业将实现最佳的分析处理能力,同时利用私有云的快速弹性 (rapid elasticity) 和单一租赁的特性。如何协同效用和实现部署,是本文希望解决的问题。
人们曾普遍认为传统数据库支持ACID和SQL等特性限制了数据库的扩展和处理海量数据的性能,因此尝试通过牺牲这些特性来提升对海量数据的存储管理能力,但是现在一些人则持有不同的观念,他们认为并不是ACID和支持SQL的特性,而是其他的一些机制如锁机制、日志机制、缓冲区管理等制约了系统的性能,只要优化这些技术,关系型数据库系统在处理海量数据时仍能获得很好的性能。
大数据是当下IT领域最活跃的话题之一。没有比近日在圣何塞举行的Hadoop Summit 2013更好的地方去了解关于大数据的最新动态了。

众所周知,intel在CPU 和芯片技术上颇有经验,尤其是为个人电脑和数据中心提供处理器和芯片。随着信息技术的发展,人与人之间的距离越来越近,intel不再关注如何拉近人们之间的距离,而是如何让用户体验灵活和方便。而大数据的蓬勃发展让intel找到了全新的市场策略。
致力于提高数据分析速度的大数据初创企业DataTorrent刚刚获得800万美元融资。这家初创企业声称可以将数据处理速度从实时提高到“现在时(now time)”。致力于提高数据分析速度的大数据初创企业DataTorrent刚刚获得800万美元融资。

说到大数据,不得不提的就是阿里巴巴。这家全球领先的电子商务企业,每天处理的数据量是其他任何公司都无法比拟的,它也正在转型成为一家真正意义上的数据公司——MySQL就是阿里巴巴转型的重要武器。曾经采访过阿里的一位数据库架构师,他认为阿里将开源MySQL的性能达到最佳状态,超越任何关系型数据库和NoSQL。

在数据库市场中,微软的SQL Server是最受关注的产品之一。在数据库知识网站DB-Engines每月公布的数据库流行度排行榜中,SQL Server几乎稳占第二名的位置。但从这个榜单每月的变化中也可以看出,大量NoSQL数据库的排名不断上升,已经开始威胁到传统数据库的地位。
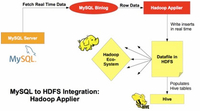
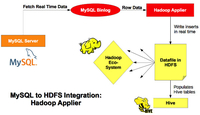
为了支持日渐强调实时性操作,我们正发布一个新MySQL Applier for Hadoop(用于Hadoop的MySQL Applier)组件。它能够把MySQL中变化的事务复制到Hadoop / Hive / HDFS。Applier 组件补充现有基于批处理Apache Sqoop的连接性。
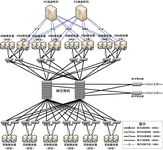
为推进全网数据流量的精细化经营,提升数据流量经营效益,河南移动与曙光公司合作进行经分系统流量经营分析工程的建设。河南移动的资源池项目是构建内部共享的业务支撑云,本项目建设是着眼于未来业务计算需要,实现根据竞争情况和客户需求,加快实现流量的实时计费和提醒,优化数据流量资费体系,降低套餐内外的资费水平差距,提高精细化营销能力,不断提高客户的满意度和大幅度降低流量投诉。
移动互联网时代的来临,给人们的生活和娱乐方式带来了天翻地覆的变化,尤其是3G网络的出现,使得人们已经突破了时间和空间的限制,随时随地都可与他人交流沟通。这一全新事物的迅猛发展,给电信运营商带来许多商机,同时也出现了一些挑战。例如随着移动互联网的普及,用户移动数据流量迅猛增长,数据流量收入已经超过了点对点短信业务,成为拉动数据业务收入增长的主要驱动力。
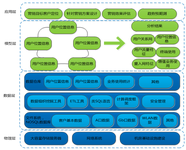
金融行业信息化已经逐渐普及,但是随着互联网技术和应用的飞速发展,尤其是发卡量和网上交易量激增,如何对这些个性化的交易进行监管和交易行为进行分析,欺诈侦测,发现和驱动新的业务,相关业务数据量急剧上升,是当前金融业在面临大数据的难题,同时由于关系型数据库的架构在面临大数据处理的先天性不足的原因,金融业亟待新的方法和技术来解决这些问题,以满足新的需求,推动业务持续快速的发展。

商业软件的版本更新非常快,而每次更新所添加的“新特性”是用户最为关注的,而基于Apache Hadoop的产品也是如此。想要让Hadoop真正为企业所用,并不断扩展其用例,新特性是必不可少的。
大数据仍然处于初级阶段。在可以预见的未来,大数据核心技术以及应用仍将以飞快的速度不断变化。数据仓库项目通常包含业务逻辑分析、数据建模、ETL开发、报表开发、数据集市开发以及运营支持等阶段。但一个基于Hadoop的大数据项目不仅包含上述的阶段,还要持续同步地进行,团队成员需要紧密协作。为了大数据项目的最终成功,企业IT部门需要成立一个综合的团队,能够应对大数据每个方面所带来的挑战。
MySQL复制操作可以将数据从一个MySQL服务器(主)复制到其他的一个或多个MySQL服务器(从)。试想一下,如果从服务器不再局限为一个MySQL服务器,而是其他任何数据库服务器或平台,并且复制事件要求实时进行,是否可以实现呢?MySQL团队最新推出的 MySQL Applier for Hadoop(以下简称Hadoop Applier)旨在解决这一问题。
大数据分析和数据仓库解决方案厂商Teradata天睿公司宣布,成为业内独家向业务分析师提供优化、自助、低成本访问Apache Hadoop解决方案的厂商。通过Teradata企业级Hadoop访问工具(Teradata Enterprise Access for Hadoop),帮助他们实现更快、更加明智的战略业务决策。作为Teradata统一数据架构(UDA)的重要组件,这项全新技术使业务分析师能够通过Teradata直接访问Hadoop,从海量、各种格式的大数据中分析发现新的商业价值。
Hadoop将MapReduce并行计算带入主流应用。然而,随着大数据需求和使用模式的扩大,Hadoop已暴露出诸多局限性。《超越Hadoop的大数据:未来的研究方向》课程介绍了英特尔与大学合作伙伴为超越这些限制所进行的合作研究,并强调了为将部分成果应用到生产环境所进行的努力。



- 40位软件名人榜单出炉,60后占半壁江山!
- 于企业应用程序而言,Go比Java更明智!
- 从0到700万,钉钉只用3年,原因就是快准狠!
- 网络间谍竟持续8年活跃于中国 终被成功捕获
- "漏洞攻击拦截"功能助火绒企业产品C位出道
- MWC 2018上海:大量5G智能概念产品亮相
- 三大角度PK,Go语言和Node.js谁胜谁负?
- 思科曹图强:勒索软件将打破安全防御平衡
- 服务器价格指导 6月双路塔式服务器选购
- 佳能全力助推 设计研究院文印转印升级
- 安装到部署 火绒安全企业新品究竟有多"简"?
- 618盛况空前 斐讯商城祭出了“杀手锏”
- 玩转toB安全市场! 火绒企业安全产品评测
- 速看 斐讯天天链N1“掘金”上手攻略完整版
- 40位软件名人榜单出炉,60后占半壁江山!
- 区块链原理是什么?如何开发区块链程序?
- 区块链技术的这些特征 你都了解哪些?
- 于企业应用程序而言,Go比Java更明智!
- Java生态系统面临的最大问题是质量恶化
- 6.18大促全场大放价! 斐讯祭出几款无线神器










