CUDA开发
在 Heresy 寫的前兩篇 sample 程式(VectorAdd、DeviceInfo)裡,都是很簡單的程式;像 VectorAdd 裡,也是刻意把 vector size 設小,避掉 thread 數目超過 block 限制的問題,以避免要用到複數個 block。但是實際上,應該都是會超過 thread block 的大小限制的(畢竟 G80 的 block 大小只有到 512…)~

今天尝试用cuda把FFT实现,遇到了难题。直接调用cufft库的话,内存拷贝与数据处理的时间比大约是1:2。但是据说cufft并不是最高效的,所以想自己锻炼一下。
通用的一些接口,前一章节也有提高过:数学函数,时间函数,同步函数,原子操作; 2.控制Device的函数;就是得到设备信息,管理设备信息的函数。设置那块显卡工作,得到那块显卡的性能。
以下为VS2005的配置,VS2003和VS2008与此类似。 1、安装Visual Studio 2005环境。 2、安装开发助手Visual Assist X。 3、从 http://www.nvidia.cn/object/cuda_get_cn.html 下载CUDA相关软件,并按次序安装。
纹理存储器(texture memory)是一种只读存储器,由GPU用于纹理渲染的的图形专用单元发展而来,因此也提供了一些特殊功能。纹理存储器中的数据位于显存,但可以通过纹理缓存加速读取。在纹理存储器中可以绑定的数据比在常量存储器可以声明的64K大很多,并且支持一维、二维或者三维纹理。在通用计算中,纹理存储器十分适合用于实现图像处理或查找表,并且对数据量较大时的随机数据访问或者非对齐访问也有良好的加速效果。
开始接触CUDA,我安装好后完全不知道怎么运行demo,当然也没有见到详细的安装说明。下面说说我的经验。
以下内容摘自CUDA编程手册 版本2.1 并参考并引用了2.0中文版编程手册中的内容,并修正了一些术语和错误。本章节介绍CUDA编程模型的主要的概念并勾画出其是如何以C的形式进行表述。关于对应CUDA的C的描述的更加详细的内容将会在第四章给出。
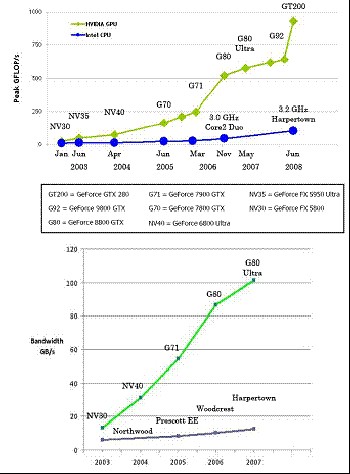
CUDA和支持CUDA的设备正在共同发展,在新一代产品中提供了更多的性能和功能。NVIDIA最近引入的GeForce 200系列和Tesla 10系列产品,展示了这种发展的迅速,其硬件功能几乎是上一产品线同一价格水平可用功能的两倍,而且200系列还增加了一些有价值(而且不可或缺)的新功能。
本专栏细心的读者已经了解了之前专栏中讨论的两个反向数组示例,可能对为什么共享存储器版本比全局存储器版本速度更快仍然感到困惑。请回想一下共享存储器版本reverseArray_multiblock_fast.cu,内核将数组数据从全局存储器复制到共享存储器,然后再复制回全局存储器,而较慢的内核reverseArray_multiblock.cu只将数据从全局存储器复制到全局存储器。因为全局存储器性能比共享存储器慢100-150倍,所以慢得多的全局存储器性能占据了两个示例的绝大部分运行时。为什么共享存储器版本更快?
平时我们使用的内存都是Pageable(交换页)的,而另一个模式就是Pinned(Page-locked),实质是强制让系统在物理内存中完成内存申请和释放的工作,不参与页交换,从而提高系统效率,需要使用cudaHostAlloc和cudaFreeHost来分配和释放。
受到来自实时、高分辨率3D图形的市场的永不满足需求的推动,可编程的图像处理单元(Graphic Processor Unit, GPU)演化为具备强大计算能力以及高内存带宽的高度的并行性,多线程性,多核处理器 。
CUDA 架构构建在一个可伸缩的多线程流处理器(Streaming Multiprocessors ,SM)之上。当主机 CPU 上的 CUDA 程序调用内核网格时,网格的块将被枚举并分发到具有可用执行容量的多处理器上。一个线程块的线程在一个多处理器上并发执行。在线程块终止时,将在空闲多处理器上启动新块。
局部内存空间和全局内存空间不会缓存,这意味着每次对全局内存(或局部内存)进行访问都将导致一次实际的内存访问。那么访问(例如读取或写入)各种类型的内存的开销是多少?
CUDA开发人员面临的最重要的性能挑战之一就是如何充分利用本地多处理器内存资源,如共享内存、常量内存,以及寄存器。原因就是我们上一篇文章中讨论的,虽然全局内存可以提供超过60 GB/秒的速度,但这对于只获取使用一次的数据来说,仅相当于15gf/秒――要获得更高的性能则要求能够重用本地数据。CUDA软件和硬件设计师做了一些出色的工作,以隐藏全局内存的延迟和全局内存的带宽限制――但这都是以本地数据重用为前提的。
CUDA的编译器为nvcc,nvcc将各种编译工具集成起来,这些编译工具实现了编译的不同阶段。nvcc的基本工作流是将device代码从host代码中分离出来,然后将其编译成二进制或者cubin工程。在执行过程中,将忽略host代码,而将device代码加载并通过CUDA的设备API来执行。
目前 NVIDIA 提供的 CUDA Toolkit支持 Windows (32 bits 及 64 bits 版本)及许多不同的 Linux 版本。
在使用CUDA进行GPGPU计算时,global + shared的黄金组合在速度上远远超过了texture,只有在以下两种情况下使用texture。
访问global虽然仍然需要最多数百个时钟周期,但是总的来说比cpu的内存还是快多了...如果使用得当的话。CUDA是符合SIMD-PRAM模型的,也就是n台功能相同的处理机(block看成处理机,每个thread看成处理机的一部分更好些),一个容量无限大的共享处理器M。其中M就是global memory,虽然在CUDA中也是有限的,但是比起可怜的shared还是多很多了。
纹理可以在线性内存或是CUDA数组(纹理内存)的任何区域。所以纹理拾取也就对存在与线性内存或CUDA数组中的纹理读取数据。


- 40位软件名人榜单出炉,60后占半壁江山!
- 于企业应用程序而言,Go比Java更明智!
- 从0到700万,钉钉只用3年,原因就是快准狠!
- 网络间谍竟持续8年活跃于中国 终被成功捕获
- "漏洞攻击拦截"功能助火绒企业产品C位出道
- MWC 2018上海:大量5G智能概念产品亮相
- 三大角度PK,Go语言和Node.js谁胜谁负?
- 思科曹图强:勒索软件将打破安全防御平衡
- 服务器价格指导 6月双路塔式服务器选购
- 佳能全力助推 设计研究院文印转印升级
- 安装到部署 火绒安全企业新品究竟有多"简"?
- 618盛况空前 斐讯商城祭出了“杀手锏”
- 玩转toB安全市场! 火绒企业安全产品评测
- 速看 斐讯天天链N1“掘金”上手攻略完整版
- 40位软件名人榜单出炉,60后占半壁江山!
- 区块链原理是什么?如何开发区块链程序?
- 区块链技术的这些特征 你都了解哪些?
- 于企业应用程序而言,Go比Java更明智!
- Java生态系统面临的最大问题是质量恶化
- 6.18大促全场大放价! 斐讯祭出几款无线神器










