分布式文件系统
英特尔认为,随着一些新兴的IT技术兴起,如微博、平安城市、医疗以及企业云等,将使得传统的存储解决方案很难应对这些挑战。因为这些应用或者方案大多都是以海量的非结构化数据为主,不管是在容量、性能、价格、灵活性、容错或响应速度方面,如果用传统的纵向扩展存储解决方案去解决的话,将付出高昂的代价,但结果未必能够令人满意。而这正是横向扩展存储所能体现优势的地方。

PCIe SSD和闪存卡提供了比任何其它非易失性解决方案更快的存储访问,但PCIe存储的缺点是,它只能从PCIe卡插入的服务器是访问和管理。这当服务器崩溃时能够成为一个实际的问题,你的数据会被困在里面。Virident的FlashMAX Fabric软件通过使PCIe闪存的行为更像是一个SAN或者作为一个分布式的缓存,解决了这个问题。

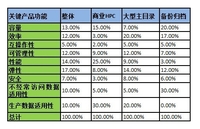
对于IT主管来说,为大数据构建一个同时具有高可扩展性和成本效益的存储基础架构是非常关键的,也是必要的。日前,Garter对目前市场主流的九大存储供应商所推出的9款横向扩展文件系统产品进行了对比评测分析,并指出了各自的有点和需改进的地方,以供用户在采购时进行对比参考,以下为报告主要内容(注:本译文部分有删减):
作为全球最大的社交网站,Facebook每天要处理大量的数据。而Facebook的成长过程都包含了哪些数据天才的智慧呢?近日知名科技网站Wired发表文章向人们介绍了Facebook崛起背后的数据英雄。


分布式文件系统是微软服务器中很重要的一项功能。通过分布式文件系统网络管理员可以将服务器文件分散存储到网络上的多台服务器上,以提高服务器性能并增强服务器的容错性。
最近很多人都在讨论Spark这个貌似通用的分布式计算模型,国内很多机器学习相关工作者都在研究和使用它。Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发。那么Spark和Hadoop有什么不同呢?
数据存储主要有两种方式:Database和FileSystem,后面发展出了Object-oriented storage,但是总的来看就是存储结构化和非结构化数据两种。 DB开始是为了结构化数据存储和共享而服务的。FileSystem存储和共享的是大文件,非结构的数据,像图片,文档,影音等。随着数据量的增大……
58同城是位于北京的分类信息网站,提供房产、招聘、黄页、团购、交友、二手、宠物、车辆、周边游等海量分类信息。58在google top1000全球网站排行版中排名在50-60左右

时下,“大数据”已逐渐成为人们热议的名词之一。据IDC预测,到2020年,全球数据总量将增长50倍,其中80%为非结构化数据。
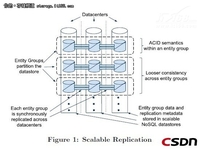
Megastore是谷歌一个内部的存储系统,它的底层数据存储依赖Bigtable,也就是基于NoSql实现的,但是和传统的NoSql不同的是,它实现了类似RDBMS的数据模型,同时提供数据的强一致性解决方案,并且将数据 进行细颗粒度的分区,然后将数据更新在机房间进行同步复制 。
最新的VMware旗舰产品vSphere平台支持虚机负载平衡,vSphere早就有的DRS(分布式资源调度)功能能够帮助整个集群中通过主机实现负载均衡。然而直到现在,DRS仍只是一个概念,其只能对正在进行的虚机进行负载均衡。vSphere 5.0的发布,将负载均衡理念延伸到了虚拟机磁盘文件系统。
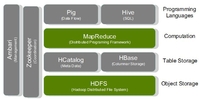
谈到分布式系统,就不得不提Google的三驾马车:Google fs[1],Mapreduce[2],Bigtable[3]。虽然Google没有公布这三个产品的源码,但是他发布了这三个产品的详细设计论文。而且,Yahoo资助的Hadoop也有按照这三篇论文的开源Java实现:Hadoop对应Mapreduce, Hadoop Distributed File System。
Hadoop的创始源头在于当年Google发布的3篇文章,被称为Google的分布式计算三驾马车(Google还有很多很牛的文章,但是在分布式计算方面,应该这三篇的影响力最大了):http://blog.sina.com.cn/s/blog_4ed630e801000bi3.html,链接的文章比我介绍得更清晰,这是做分布式系统、分布式计算的工程师必修课。

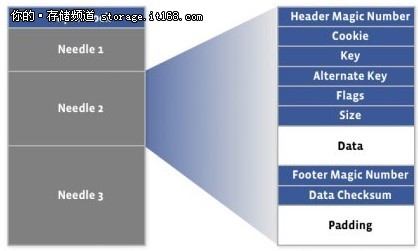
HayStack是Fackbook用于存储照片的系统,其存储照片的数量在千亿数量级,本文简要分析HayStack的设计与实现原理
IBM科学家宣称,该设计在将万亿字节的数据变成可用的信息方面,速度比当前技术可以提高两倍。因此,该设计非常适用于云计算和数据密集型的工作负载应用场合
简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,但可以提供容错功能。它可以给大量的用户提供总体性能较高的服务


- 40位软件名人榜单出炉,60后占半壁江山!
- 于企业应用程序而言,Go比Java更明智!
- 从0到700万,钉钉只用3年,原因就是快准狠!
- 网络间谍竟持续8年活跃于中国 终被成功捕获
- "漏洞攻击拦截"功能助火绒企业产品C位出道
- MWC 2018上海:大量5G智能概念产品亮相
- 三大角度PK,Go语言和Node.js谁胜谁负?
- 思科曹图强:勒索软件将打破安全防御平衡
- 服务器价格指导 6月双路塔式服务器选购
- 佳能全力助推 设计研究院文印转印升级
- 安装到部署 火绒安全企业新品究竟有多"简"?
- 618盛况空前 斐讯商城祭出了“杀手锏”
- 玩转toB安全市场! 火绒企业安全产品评测
- 速看 斐讯天天链N1“掘金”上手攻略完整版
- 40位软件名人榜单出炉,60后占半壁江山!
- 区块链原理是什么?如何开发区块链程序?
- 区块链技术的这些特征 你都了解哪些?
- 于企业应用程序而言,Go比Java更明智!
- Java生态系统面临的最大问题是质量恶化
- 6.18大促全场大放价! 斐讯祭出几款无线神器










