大数据
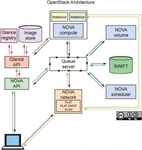
这两种答案都有企业在实践。“Hadoop跑在OpenStack上”可以参考《Project Savanna:让Hadoop运行在OpenStack之上》,“OpenStack部署到Hadoop上”则重点可查阅本文。随着企业开始同时利用云计算和大数据技术,现在应当考虑如何将这些工具结合使用。在这种情况下,企业将实现最佳的分析处理能力,同时利用私有云的快速弹性 (rapid elasticity) 和单一租赁的特性。如何协同效用和实现部署,是本文希望解决的问题。
医疗信息化到底解决什么问题?早在20年前的有线网时代,医院信息化考虑的是以部门为核心的信息系统,医院以科室为单位,由不同的提供商提供其医疗IT解决方案。如今,随着移动、物联网、大数据技术的发展,“数据”带来的巨大价值正渐渐被人们认可,从无线查房、移动护理、电子病历到患者服务、医疗应用、移动办公……中国的医疗行业快速掀起了一波强劲的医疗解决方案的浪潮。

然而,不管是哪种定义,似乎都否定了传统数据库在大数据市场的作用。面对不断增长的数据量和多样的数据类型,很多企业用户选择NoSQL和Hadoop替代原有数据库,Facebook和Twitter就是这其中的典型。据IDC预计,2015年大数据技术和服务市场将增长至169亿美元,年复合增长率达40%,大量创新型企业涌入大数据市场,威胁到传统数据库厂商的地位。

前不久的“棱镜门”让国人认识到发展国产软件的重要性,也被认为是国产数据库发展的重要契机。国产数据库在过去发展中一直受到国家的支持,但由于起步较晚,与国外主流数据库之间的差距还很大。但随着大数据时代的到来,国产数据库与国外数据库站在同一起跑线上,获得同样的机遇。
大数据趋势在2012年开始变得明显,Hadoop、NoSQL等技术的兴起,令传统数据库稳固的江山开始动摇。“以不变应万变”不再是大数据时代应有的策略,老牌数据库厂商在保持传统市场领先的基础上,不断拓展新市场。

去年是“云计算”,今年是“大数据”。作为时下最流行的信息化“标志”,如今每个行业都在为自己具备“大数据”能力而作出努力。一时间,似乎不说自己有“大数据”基因,或者正在做着“大数据”相关的事情,都觉得自己赶不上潮流了。但是最近被炒得如火如荼的“棱镜门”事件却犹如一记响亮的耳光重重地拍在了“大数据”的“脸上”,让一直对“大数据”趋之若鹜的公众对其又有了全新的认识。
什么职业最性感?也许你会说是运动员、艺术家或者演员,其实不然。《哈佛商业评论》认为“数据科学家”是二十一世纪最性感的职业。很多人还不知道什么是数据科学家,更不能理解为什么数据科学家最性感。其实数据科学家是由Natahn Yau在2009年首次提出的,其概念是采用科学方法、运用数据挖掘工具寻找新的数据洞察的工程师。

IBM对数据库领域的贡献远不止DB2那么简单。不管是关系型数据库理论,还是SQL语言,都出自IBM。这两大理论对整个数据库行业而言举足轻重,几乎所有主流数据库都建立在此基础上。然而,刚刚过完30岁生日的DB2在数据库领域的地位大不如前,IBM官方也很少单独提到DB2,而是把它作为大数据解决方案的一个模块。
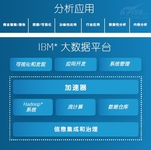
在数据库市场中,微软的SQL Server是最受关注的产品之一。在数据库知识网站DB-Engines每月公布的数据库流行度排行榜中,SQL Server几乎稳占第二名的位置。但从这个榜单每月的变化中也可以看出,大量NoSQL数据库的排名不断上升,已经开始威胁到传统数据库的地位。
在收购Sybase之前,SAP还不算是个数据库厂商,但其在ERP市场的地位举足轻重。那时的SAP只能通过与其他厂商合作来满足其商务套件的数据库需求,其中最大的合作伙伴就是甲骨文。SAP每年销售约10亿美元的甲骨文数据库,这对于SAP而言就如同在竞争对手的身上撒钱。
云计算和大数据目前都是热门话题,如何把两者结合起来即在云上实现大数据项目,这是一个新的实践领域。资深数据专家David Gillman根据自己的经验,列举了云上大数据方案需要考虑的基本要素,包括对数据构建实时索引、自由模式搜索与分析、监视数据并提供实时警告等,帮助用户更好地评估和选择解决方案。
联合国2012年发布了《大数据促发展:机遇与挑战》报告。报告指出,世界正经历着一场数据革命,而这一革命并不局限于工业化世界,发展中国家和地区同样会产生出大量的实时信息流。由于世界正变得越来越难以控制,而事物之间存在着相互联系,制定者更倾向于利用这些关系,采用更为简单廉价的方式来防止世界不稳定因素造成的损害或将这种损害保持在最低限度。
6月16日,对于世贸天阶来说可以说是大数据的一天,IBM连线大数据与分析活动在此举行。在这聚集时尚前沿的阵地上,IBM再次与我们公话“大数据”这一当今最热的名词。放眼业界窥得大数据真谛者有几家?

“大数据”是“数据化”趋势下的必然产物!数据化最核心的理念是:“一切都被记录,一切都被数字化”。最近2年所产生的数据量等同于2010年以前整个人类文明产生的数据量总和,更重要的是,数据来源极大丰富,形成了多源异构的数据形态,其中非结构化数据所占比重逐年增大。
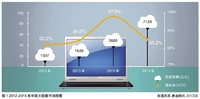
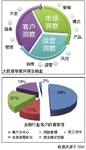
目前,中国的金融行业数据量已经超过100TB,非结构化数据迅速增长。IDC认为中国金融行业正在步入大数据时代的初级阶段。优秀的数据分析能力是当今金融市场创新的关键,资本管理、交易执行、安全和反欺诈等相关的数据洞察力,成为金融企业运作和发展的核心竞争力。基于SunGard对于大数据的发展趋势分析,大数据在存储和处理框架方面的优势将帮助金融企业充分掌握业务数据的价值,降低业务成本并发掘新的盈利机会。
如果有人问“谁将成为谷歌的大数据?”,唯一可以接受的答案是“谷歌是谷歌的大数据”。没错,谷歌表面看起来是一家网络公司,但实际上它已经成为利用数据进行创新方面的领导者,且这一领导地位自其成立开始,从未显示出任何放缓的迹象。

2013年6月20日消息,首届SAS中国用户大会暨商业分析领袖峰会今天在北京举行,这是SAS全球论坛(SAS Global Forum) 首次登陆中国,会议主题围绕“大数据、大分析、大智慧、大价值”展开。SAS全球高级副总裁兼首席技术官Keith Collins、SAS公司大中华区总裁吴辅世、经济学人亚洲区行业与管理研究执行总编David Line、SAS北亚区首席技术官Deepak Ramanathan等出席了本次大会,并发表主题演讲。

本文介绍了Google的大数据分析工具BigQuery,如果你对SQL比MapReduce更熟悉,而关系型数据库尚不能满足你的分析需求,那么可以考虑使用Google的BigQuery。
对运营商乃至整个电信业而言,大数据涵义有多个层面:来自OTT(互联网企业越过运营商,发展基于互联网的各种视频和数据服务业务)服务商的威胁不容小觑,电信业拥有丰富的大数据资源,以及电信业拥有足够的大数据分析能力并非难事,电信业开展新业务尤其是BI(商业智能)的潜力巨大。

十年前,曙光公司就提出了从硬件提供商向信息服务提供商转型的口号。四年前,曙光公司又发布了云计算战略。从单纯提供硬件产品到提供整体解决方案再到提供云服务,曙光公司的转型步伐稳健而坚定。
.jpg)


- 40位软件名人榜单出炉,60后占半壁江山!
- 于企业应用程序而言,Go比Java更明智!
- 从0到700万,钉钉只用3年,原因就是快准狠!
- 网络间谍竟持续8年活跃于中国 终被成功捕获
- "漏洞攻击拦截"功能助火绒企业产品C位出道
- MWC 2018上海:大量5G智能概念产品亮相
- 三大角度PK,Go语言和Node.js谁胜谁负?
- 思科曹图强:勒索软件将打破安全防御平衡
- 服务器价格指导 6月双路塔式服务器选购
- 佳能全力助推 设计研究院文印转印升级
- 安装到部署 火绒安全企业新品究竟有多"简"?
- 618盛况空前 斐讯商城祭出了“杀手锏”
- 玩转toB安全市场! 火绒企业安全产品评测
- 速看 斐讯天天链N1“掘金”上手攻略完整版
- 40位软件名人榜单出炉,60后占半壁江山!
- 区块链原理是什么?如何开发区块链程序?
- 区块链技术的这些特征 你都了解哪些?
- 于企业应用程序而言,Go比Java更明智!
- Java生态系统面临的最大问题是质量恶化
- 6.18大促全场大放价! 斐讯祭出几款无线神器










